本文共 2774 字,大约阅读时间需要 9 分钟。
本节书摘来异步社区《R数据可视化手册》一书中的第3章,第3.10节,作者:【美】Winston Chang,更多章节内容可以访问云栖社区“异步社区”公众号查看。
3.10 绘制Cleveland点图
问题
如何绘制Cleveland点图?方法
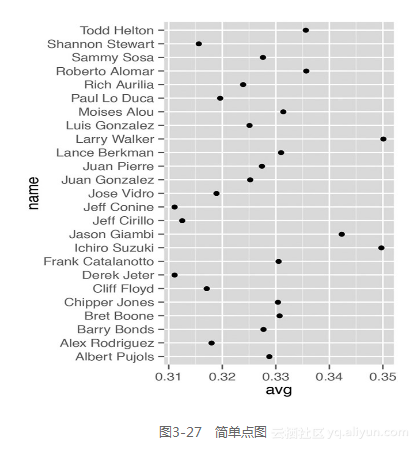
有时人们会用Cleverland点图来替代条形图以减少图形造成的视觉混乱并使图形更具可读性。最简便的绘制Cleverland点图的方法是直接运行geom_point()命令(见图3-27)。
library(gcookbook) # 为了使用数据tophit <- tophitters2001[1:25, ] # 取出tophitters数据集中的前25个数据ggplot(tophit, aes(x=avg, y=name)) + geom_point()
讨论
tophitters2001数据集包含很多列,这里我们只看其中三列:tophit[, c("name","lg","avg")] name lg avg Larry Walker NL 0.3501 Ichiro Suzuki AL 0.3497 Jason Giambi AL 0.3423... Jeff Conine AL 0.3111 Derek Jeter AL 0.3111 图3-27中的名字是按字母先后顺序排列的,这种排列方式用处不大。通常,点图中会根据x轴对应的连续变量的大小取值对数据进行排序。
尽管tophit的行顺序恰好与avg的大小顺序一致,但这并不意味着在图中也是这样排序的。在点图的默认设置下,坐标轴上的变量通常会根据变量类型自动选取合适的排序方式。本例中变量name属于字符串类型,因此,点图根据字母先后顺序对其进行了排序。当变量是因子型变量时,点图会根据定义好的因子水平顺序对其进行排序。现在,我们想根据变量avg对变量name进行排序。
我们可以借助reorder(name,avg)函数实现这一过程。该命令会先将name转化为因 子,然后,根据avg对其进行排序。为使图形效果更好,我们借助图形主题系统(Theming System)删除垂直网格线,并将水平网格线的线型修改为虚线(见图3-28)。
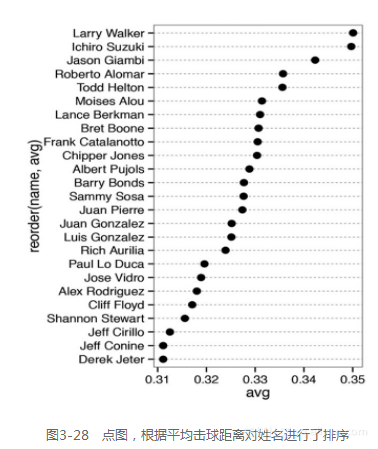
ggplot(tophit, aes(x=avg, y=reorder(name,avg))) + geom_point(size=3) + # 使用更大的点 theme_bw() + theme(panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(), panel.grid.major.y = element_line(colour="grey60", linetype="dashed"))
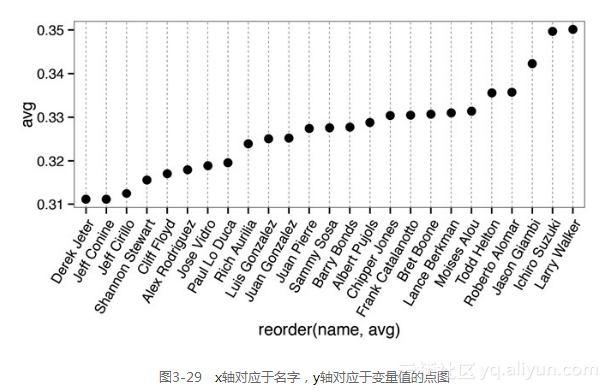
我们也可以将点图的x轴和y轴互换,互换后,x轴对应于姓名,y轴将对应于数值,如图3-29所示。我们也可以将数据标签旋转60°。
ggplot(tophit, aes(x=reorder(name, avg), y=avg)) + geom_point(size=3) + # 使用更大的点 theme_bw() + theme(axis.text.x = element_text(angle=60,hjust=1), panel.grid.major.y = element_blank(), panel.grid.minor.y = element_blank(), panel.grid.major.x = element_line(colour="grey60", linetype="dashed"))
有时候,根据其他变量对样本进行分组很有用。这里我们根据因子lg对样本进行分组,因子lg对应有NL和AL两个水平,分别表示国家队(National League)和美国队(American league)。我们依次根据lg和avg对变量进行排序。遗憾的是,reorder()函数只能根据一个变量对因子水平进行排序,所以我们只能手动实现上述过程。
# 提取出name变量,依次根据变量lg和avg对其进行排序nameorder <- tophit$name[order(tophit$lg, tophit$avg)]# 将name转化为因子,因子水平与nameorder一致tophit$name <- factor(tophit$name, levels=nameorder)
绘制点图时(见图3-30),我们把lg变量映射到点的颜色属性上。借助geom_segment()函数用“以数据点为端点的线段”代替贯通全图的网格线。注意geom_segment()函数需要设定x、y、xend和yend四个参数:
ggplot(tophit, aes(x=avg, y=name)) + geom_segment(aes(yend=name), xend=0, colour="grey50") + geom_point(size=3, aes(colour=lg)) + scale_colour_brewer(palette="Set1", limits=c("NL","AL")) + theme_bw() + theme(panel.grid.major.y = element_blank(), # 删除水平网格线 legend.position=c(1, 0.55), # 将图例放置在绘图区域中 legend.justification=c(1, 0.5)) 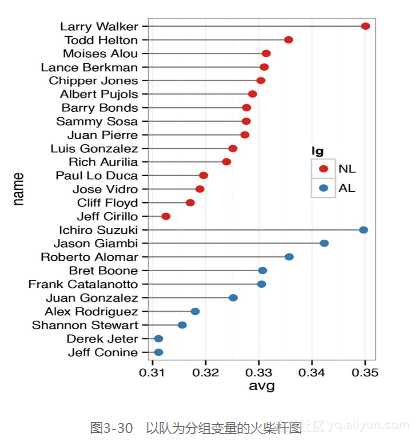
另外一种分组展示数据的方式是分面,如图31所示。分面条形图中的条形的堆叠顺序与图3-30中的堆叠顺序有所不同;要修改分面显示的堆叠顺序只有通过调整lg变量的因子水平来实现。
ggplot(tophit, aes(x=avg, y=name)) + geom_segment(aes(yend=name), xend=0, colour="grey50") + geom_point(size=3, aes(colour=lg)) + scale_colour_brewer(palette="Set1", limits=c("NL","AL"), guide=FALSE) + theme_bw() + theme(panel.grid.major.y = element_blank()) + facet_grid(lg ~ ., scales="free_y", space="free_y") 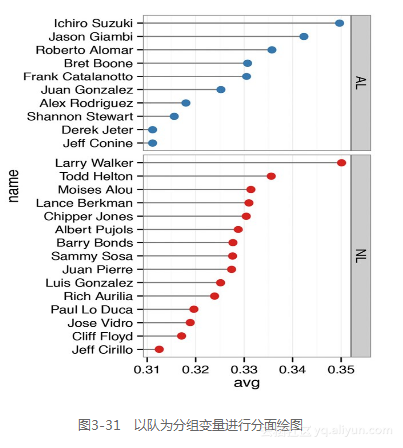
转载地址:http://itqjl.baihongyu.com/